99%는 괜찮은데 1%가 문제다
Feature Flag 도입 후 a/b 테스트 등에서 evaluation 결과를 분석할 수 있는 s3 export 기능을 추가했다. 각 파드에서 1분에 한번씩 축적된 evaluation 결과를 s3 로 보내는 기능으로, 평소에는 큰 문제 없었지만 s3 재시도 문제와 p99 latency 가 튀는 이슈가 있었다. p95 레이턴시는 1ms 내외 수준이지만 p99는 순간 수치가 3초 이상으로 치솟는 케이스가 간헐적으로 발생했다. 99%의 요청은 깔끔하게 처리되는데 나머지 1%는 블로킹되는 상황으로 파악했다.
| 지표 | 값 |
|---|---|
| API | GET /피쳐플래그-evaluation |
| p95 | ~1ms |
| p99 | ~3초 |
| p95와 p99 차이 | 약 3000배 |
현재 피쳐플래그에서 사용되는 인프라는 feature-flag 메타데이터를 저장하는 redis 와 evaluation 결과를 저장하는 s3 가 있다. redis 에 저장된 메타데이터는 1분에 한번 씩 조회하여 local cache 에 저장한 뒤 evalutaion 에 사용된다. 다수의 pod 에서 1분에 한번 씩 조회한들 3초 이상의 p99 latency 를 초래하는 요인으로 보긴 어려웠다. 실제로 feature flag 용 레디스를 별도로 운영했기 때문에 latency 지표를 통해 위 상황과는 무관한 점을 쉽게 파악할 수 있었다.
남은 건 S3 Exporter 인데 문제를 딥다이브 하면서 실제로는 서로 다른 두 가지 레이턴시 문제가 혼재돼 있는 걸 알게 됐다.
- 문제 1 - p99 spike: 특정 순간에 p99가 수 초~수십 초로 치솟는 현상
- 문제 2 - max 레이턴시 baseline: spike를 해결한 뒤에도 flush마다 60-70ms의 블로킹이 남아 있는 현상
두 문제 모두 mutex, 즉 공유 자원 락과 관련 있었다. mutex는 한 번에 하나의 스레드만 통과할 수 있게 하는 잠금장치로 락을 건 채로 오래 대기 시, 후속으로 실행 준비 중인 모든 스레드가 기다려야 한다. 이 글은 muxtex 락과 관련된 두 문제를 순서대로 추적하고 해결한 과정을 정리한다.
Feature Flag Evaluation API의 구조
앞서 말했듯이 Feature Flag Evaluation API는 클라이언트로부터 특정 flag key에 대한 평가 요청을 받으면 local cache에서 flag 데이터를 조회하여 boolean, string, int 등의 값을 반환하는 구조다. source data는 1분에 한번씩 Redis 조회로 가져오며, latency 는 sub-millisecond 수준이므로 평상시에 p95가 1ms 이하인 것도 자연스러운 일이었다.
bashClient ──▶ Feature Flag Service ──▶ local cache (flag 조회) ──▶ Response │ │ store evaluation event ▼ S3 Exporter (parquet)
Feature Flag 라이브러리(go-feature-flag)는 모든 evaluation 결과를 이벤트로 기록하며 일정 조건이 충족되면 이 이벤트들을 S3에 내보내는 구조를 갖는다. 평소에는 이벤트를 메모리 버퍼에 쌓기만 하므로 API 응답에 영향을 주지 않지만 flush가 발생하는 순간에는 상황이 달라진다.
flush 메커니즘
go-feature-flag 라이브러리의 DataExporter는 두 가지 조건에서 flush를 트리거한다. 첫 번째는 60초마다 실행되는 타이머 기반 flush이고, 두 번째는 메모리 버퍼에 이벤트가 100,000개 쌓이면 발생하는 버퍼 기반 flush다. 두 경우 모두 flush 과정에서 mutex 획득 후 동기식으로 S3 Export를 실행한다.
| 트리거 | 조건 | 실행 위치 |
|---|---|---|
| 타이머 기반 | 60초마다 | daemon goroutine |
| 버퍼 기반 | 100,000개 이벤트 도달 시 | request goroutine |
AddEvent()는 모든 evaluation 요청마다 호출되며 버퍼에 이벤트를 추가하기 위해 동일한 mutex를 사용한다. flush가 진행되는 동안 mutex가 잠겨 있으므로 그 사이에 들어오는 다른 모든 요청의 AddEvent() 호출이 mutex 에서 대기하고 이것이 곧 API 레이턴시 증가로 이어진다.
bashAddEvent() 호출 │ ▼ mutex.Lock() ◀── flush 중이면 여기서 대기 │ ▼ len(cache) >= 100,000? │ │ YES NO │ │ ▼ ▼ flush() cache에 (동기식) 이벤트 추가 │ ▼ S3Exporter.Export() │ └─▶ S3 Upload (~60-70ms)
여기까지가 두 문제의 공통 배경이다. flush 중에 mutex가 잠기면 다른 요청이 대기한다는 구조적 특성이 문제 1과 문제 2 모두의 출발점이었다.
문제 1: p99 레이턴시 — mutex 물고 sleep 하는 Jitter
flush 자체가 느린지, 다른 요인으로 느려지는 것인지 확인할 필요가 있었다. 디버깅 로그를 추가하여 실제 트래픽을 분석한 결과는 아래와 같다.
| 지표 | 값 | 분석 |
|---|---|---|
| event_count | ~5,000 | 버퍼 100,000의 5% 수준 |
| export_interval | ~60초 | 타이머 기반 flush (정상) |
| duration (S3 업로드) | ~60-70ms | S3 업로드 자체는 빠름 |
S3 업로드는 60-70ms 밖에 안 걸렸고 버퍼가 100,000개에 도달한 적도 없었다. 그렇다면 3초라는 latency 는 어디서 발생하는 걸까? 애플리케이션 코드에 추가된 S3 Exporter의 applyJitter() 함수에 있었다.
위 에러는 여러 pod가 동시에 S3로 업로드 시 발생하는 thundering herd 문제로 S3가 503을 반환하며 최대 재시도 횟수를 초과시 발생한다. 문제 해결책으로 각 pod마다 재시도 시 0~7초의 랜덤한 간격(jitter) 을 추가하여 s3 에 요청이 몰리는 상황을 방지하려 했고 실제로 s3 throttling 이슈는 해결할 수 있었다. 하지만 jitter 의 sleep 이 mutex를 잡은 상태에서 실행되는 점이 문제였다. flush 동안 mutex를 잡은 상태에서 최대 7초간 sleep 하니, 그 시간 동안 다른 모든 요청의 AddEvent()가 대기하게 된다.
gofunc (f *S3Exporter) applyJitter(ctx context.Context) error { if f.MaxJitterMs <= 0 { return nil } jitter := time.Duration(rand.IntN(f.MaxJitterMs)) * time.Millisecond select { case <-ctx.Done(): return fmt.Errorf("interrupted") case <-time.After(jitter): // ← 최대 7초 sleep return nil } }
Jitter 비활성화
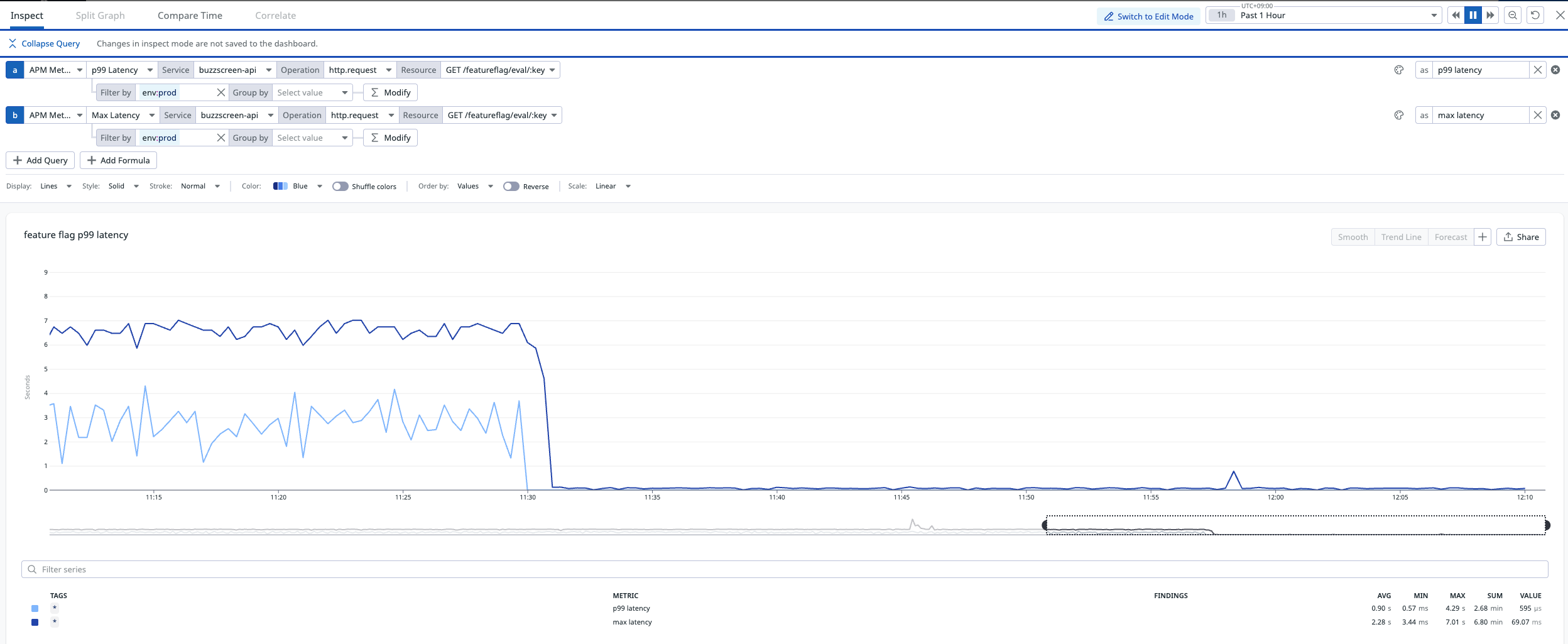
가장 즉각적인 효과를 가져온 건 Jitter를 임시로 비활성화한 PR이었다. 원인이 Jitter라는 확신이 생긴 뒤 Export 함수에서 applyJitter() 호출을 주석 처리하는 단순한 변경이었지만 효과는 극적이었다. 배포 직후 일 최대 레이턴시가 55초에서 약 200ms 수준으로 떨어졌고, 이후 지속적으로 안정적인 수치를 유지했다.
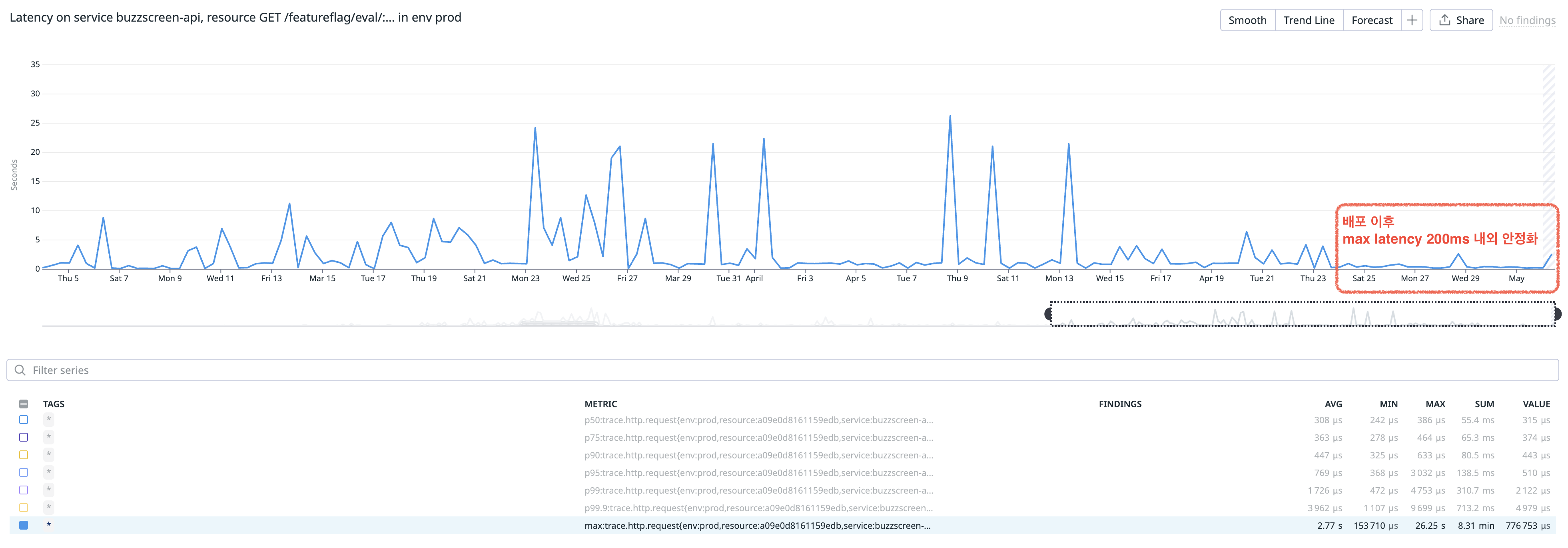
jitter 제거 후 s3 thundering herd 이슈는 export 주기를 늘리는 식으로 완화할 수 있었다. 기존에는 매 1분마다 export가 발생하여 여러 파드가 동시에 flush할 빈도가 높았지만, 이 주기를 3분으로 늘리면서 동시 flush 빈도를 줄여 S3 throttling 에러를 안정적으로 운영할 수 있었다. (완전히 제거할 수는 없었지만 그 빈도는 거의 없는 수준으로 줄었다.)
문제 2: max 레이턴시 — 동기 flush가 API를 멈추다
Jitter를 비활성화하고 export 주기를 조절하여 p99 spike 이슈는 해결했지만 max latency 또 다른 문제가 있었다. S3 업로드 자체가 60-70ms 걸리는데, flush 중에는 이 시간 동안 mutex가 잠겨 있으므로 모든 요청이 60-70ms만큼 대기하게 된다. p99.9 까지 latency 는 거의 발생하지 않게 됐지만 max latency 는 간헐적으로 튀는 부분이 보였고, flush가 발생할 때마다 모든 API 요청이 일제히 멈추는 것은 여전히 바람직하지 않았다.
AsyncExporter 래퍼 — 비동기 전환
결국 근본적인 개선은 Export 과정을 비동기로 전환하는 것이었다. 기존에는 flush 트리거 시 S3 업로드가 완료될 때까지 mutex를 잡고 기다렸지만, AsyncExporter wrapper를 도입하여 버퍼에 쌓인 이벤트를 로컬 변수로 복사한 뒤 즉시 mutex를 해제하고 S3 업로드는 별도 goroutine에서 처리하도록 변경했다. flush가 발생하더라도 다른 요청의 AddEvent()가 블로킹되는 시간이 이벤트 복사에 소요되는 마이크로초 수준으로 줄어든다.
오픈소스 기여 — mutex hold time 줄이기
서비스 측 개선과 별개로 근본 원인이 go-feature-flag 라이브러리 자체에도 있다는 점이 계속 걸렸다. 라이브러리 내부의 DataExporter 스케줄러가 flush 시 mutex를 잡은 채로 Export까지 동기 실행하는 구조 때문인데, 내부 코드의 flush 함수에서 cache를 읽고 Export를 호출하고 다시 cache를 비우는 전체 과정이 하나의 mutex lock 안에서 이루어지고 있었고, 이 구간에서 네트워크 I/O가 발생하니 mutex hold time이 불필요하게 길어지는 이슈가 발생한 것이었다.
go// 기존 코드 — ProcessPendingEvents func (e *eventStoreImpl[T]) ProcessPendingEvents(...) error { e.mutex.Lock() defer e.mutex.Unlock() // ← S3 업로드 끝날 때까지 유지 eventList, _ := e.fetchPendingEvents(consumerID) processEventsFunc(...) // ← S3 업로드 (수백 ms 블로킹) e.updateConsumerOffset(...) }
go// 변경 후 — 락 분리 (3단계) func (e *eventStoreImpl[T]) ProcessPendingEvents(...) error { // Step 1: 이벤트 조회 (짧은 락) e.mutex.Lock() eventList, err := e.fetchPendingEvents(consumerID) e.mutex.Unlock() // Step 2: Export 실행 (락 없음 — 느린 I/O) err = processEventsFunc(context.Background(), eventList.Events) // Step 3: offset 업데이트 (짧은 락) e.mutex.Lock() err = e.updateConsumerOffset(consumerID, eventList.NewOffset) e.mutex.Unlock() }
위 문제를 해결하기 위해 PR을 제출했다. 핵심 변경은 mutex hold time을 최소화하는 것으로 cache 데이터를 로컬 변수로 복사한 뒤 즉시 mutex를 해제하고 실제 Export는 mutex 밖에서 실행하도록 수정했다. 이렇게 하면 Export 과정에서 네트워크 I/O가 아무리 오래 걸리더라도 다른 goroutine의 AddEvent() 호출이 블로킹되지 않는다.
이 PR은 최종적으로 머지되었다. 이제 Jitter를 다시 활성화하더라도 sleep이 mutex 밖에서 실행되므로 thundering herd를 방지하면서 API 레이턴시에 영향을 주지 않는다.
마무리
이번 개선 과정을 돌이켜보면 두 문제 모두 결국 공유 자원을 잠근 채 I/O를 수행 이라는 동일한 원인으로 귀결되었다. 문제 1에서는 mutex를 잡고 최대 7초간 sleep하는 Jitter가, 문제 2에서는 mutex를 잡고 S3 업로드를 수행하는 동기 flush가 원인이었다. 규모만 달랐을 뿐 패턴은 동일했고 해결책도 (돌이켜보면) 단순했다.
p99 같은 tail latency 문제를 조사할 때 기억해둘 만한 점도 있었다. 평균이나 p95로는 보이지 않는 문제가 p99에서 드러나는 경우, 원인은 대부분 "가끔 발생하는 특수 경로"에 있다. 타이머 기반 flush, 버퍼 임계치 도달, 조건부 retry 같은 경로는 평소에는 실행되지 않다가 특정 조건에서만 트리거되므로 평균 지표로는 포착하기 어렵다. Datadog의 flame graph와 레이턴시 추이 그래프를 교차 분석하는 것이 이런 유형의 문제를 찾아내는 데 효과적이었다.